MCU Bootloaders: Resisting shutdowns
In the previous article, I introduced microcontrollers and how their limitations make it tricky to update them remotely, as well as what my own bootloader, called Polyboot, aims to do: reliably update boards with multiple microcontrollers.
However, to be able to reliably update multiple microcontrollers, we first need to be able to reliably update a single microcontroller. So let’s see how this is done!
This article is going to be more technical than the previous one. You should still hopefully be able to follow if you have a programming or mathematical background :)
Copies, copies everywhere
The challenge today is for our bootloader to be able to withstand a sudden, unexpected shutdown, while it tries to perform its update.
An unexpected shutdown?!
It’s likely that a microcontroller will be running off of a battery, especially since it can be very power efficient. We don’t want our device to brick itself if the battery ever runs out of charge, so we’ll need to carefully design our algorithm.
To become this resilient, there must always exist a copy of the data that we need on the flash. This is a pretty intuitive requirement: if at any point in time, some of the data needed only exists within RAM, then an unexpected shutdown at that point in time will cause issues.
 Not a great time to do something critical.
Not a great time to do something critical.
The naive solution is to simply copy the new version on top of the old one. If the device suddenly shuts down, then we can simply start the copy from zero and overwrite the partially-copied application.
This works fine, until a buggy version is pushed to the device and bricks it. If that ever happens (or rather, when that happens), you won’t have any other version to fall back to.
Why not first make a copy of the old version?
That would work, but now your application may only use a third of the available space, while the other two thirds are reserved for the new version and a copy of the old version.
If you only had 1MB of storage in your microcontroller, you went from having a comfortable 500KB of usable space to only 333KB.
Ouch!
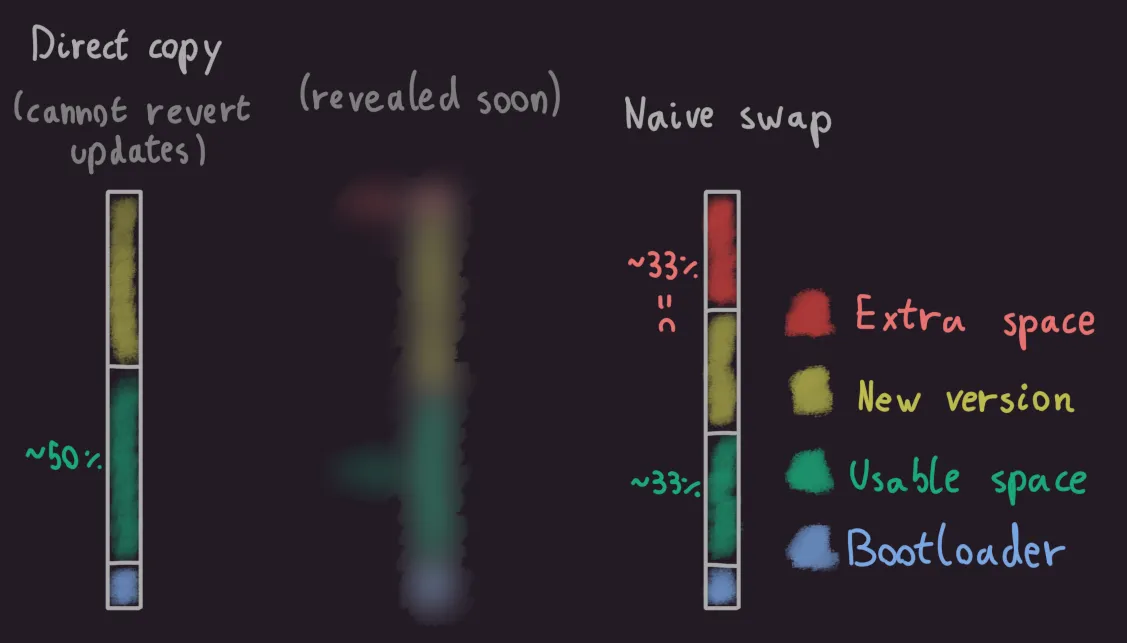
Don’t worry, though, there’s a solution to get back this lost space!
Swapping the two versions
It would be great if there was an easy way to “swap” the contents of the two versions of our application,
so that the new version ends up where it needs to go, the old version is kept around without wasting so much space.
Note from one week in the future: this is very close to how traditional A/B software updates are done.
I thought you named this chapter “Copies, copies everywhere”?
It turns out that we can do exactly that, using only copies and a tiny bit of extra, reserved space (called the scratch buffer):
- First, split the data to swap into smaller chunks.
- Then, for each chunk:
- Copy the chunk from slot
Aintoscratch. - Copy the chunk from slot
Bto the slotA. - Copy the chunk in
scratchto the slotB.
- Copy the chunk from slot
We’re essentially breaking down the problem of swapping the contents of two entire versions of an application into only needing to swap the contents of small chunks. Unlike the naive approach of reserving extra space for an entire copy of the software, we only reserve extra space for a small chunk.
We might not be getting the full 500KB of usable space, but 495KB is still a lot more acceptable than 333KB:
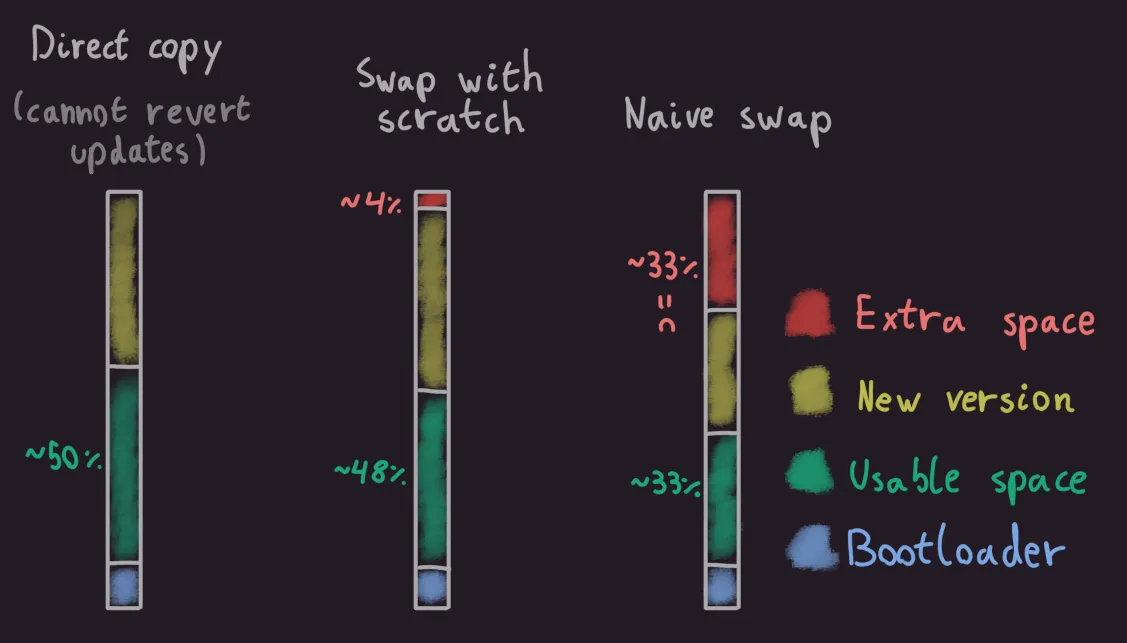 No more wasted space :)
No more wasted space :)
There is also a cheaty way to swap the contents of both versions, without needing the algorithm above, called Bank Switching.
Some microcontrollers actually do make this swapping operation easy by having a feature called Bank Switching. You might have heard of this being used on GameBoys to have more storage than the CPU could normally handle.
In our case, this feature lets us logically swap the two halves of the flash. Physically, the data is still in its original place, but the CPU is tricked into thinking that their content was swapped around.
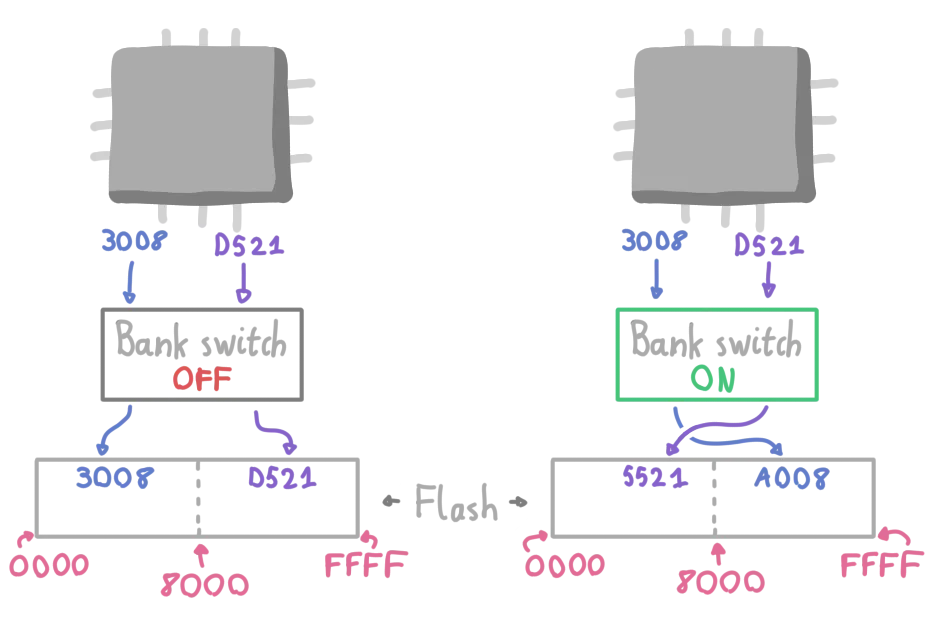 A comparison of the behavior of flash memory when bank switching is disabled or enabled.
A comparison of the behavior of flash memory when bank switching is disabled or enabled.
This is by far the best solution (you don’t need to have a scratch buffer or copy the data around), but it isn’t always available. It notably wasn’t available on one of the chips that I was working with, the nRF52840 and I cannot rely on it anyway if I want to update multiple microcontrollers.
There is one slight detail remaining now: if the device turns off mid-update, both versions would be garbled together. We somehow need to be able to find out where we left off, or else our poor little bootloader will be stuck with a Frankenstein version of our application:

Easy. Just store in the flash the number of chunks swapped and which step we were at!
Write-once memory
Aww come on :(
You were on the right track, but there is one more obstacle in our way, which is tied to how flash memory works at the circuit level. This detail only really becomes an issue when you’re designing algorithms that need to write to the flash.
Physically, flash memory can only be written to once, to switch the bits from their erased state (1) to their programmed state (0).
Once a bit has been programmed, the only way for it to go back to its erased state is to erase an entire page.
A page is usually 256 to 1024 bytes long and erasing one is a slow, energy-intensive and wearing procedure.
In our case, this means that we can’t just store the number of chunks swapped: we necessarily would need to switch bits back and forth, which can’t be done without having to erase the page whenever we want to update the counter. The flash would be worn out in no time.
Error correcting codes
Alright, I got it this time. Allocate three bits per chunk, and flip each to 0 whenever its corresponding step is performed.
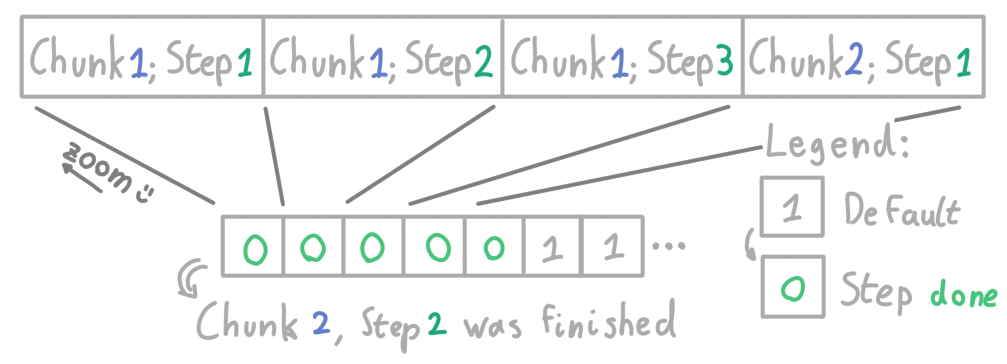 In this drawing, step 2 of the second chunk has been finished, so we can now do step 3 on that chunk.
In this drawing, step 2 of the second chunk has been finished, so we can now do step 3 on that chunk.
That’s almost it! This is what I call the journal, and it would actually work as-is on some flash devices.
Other devices, however, impose a limit on how many times you can program bits within a given word (which is usually between 8 to 64 bits long).
This is either because repeated writes have a chance of accidentally programming other bits, or, in my case, because the flash has a built-in error correcting code.
The idea of an Error Correcting Code (ECC) is to protect a piece of data from small errors, by adding a few bits to each word, in such a way that an accidental change to one bit (of the word or the additional bits) can be detected and corrected.
If we try to write in such a protected word once, then that’s usually fine, since the additional ECC bits will automatically be programmed without issue.
But, if we then try to write a second time in this word, then the ECC bits will most likely not match up cleanly and cause some serious issues, if we’re even allowed to do that in the first place.
I have an eery feeling that this “usually” will become relevant in the future…
A working journal
The solution in our case is to allocate one word per step instead of one bit per step. It doesn’t matter what we write in the words, as long as it contains some zeroes.
This is naturally more costly, but we have to keep in mind that the chunks themselves have to be one or more pages long, so there won’t be that many of them. For instance:
With 1MiB of total available space, pages of 1024 bytes and words of 64 bits (or 8 bytes);
if we chose to have chunks that are 4KiB long, then we would need at most 3KiB of space for the journal and 4KiB of scratch space.
All things considered, 7KiB is still at lot better than the 333KiB of space needed to keep an extra copy of the application. Yay!
A mathematical tangent about Error Correcting Codes and Write-Once Memory Codes
There is a clever technique around flash memory and in general write-once memory, first developped by Rivest et al. in 1982, for writing arbitrary data multiple times. (‘How to reuse a “write-once” memory’, Rivest et al., Information and Control, 1982)
Using a few extra bits, one can encode the data in such a way that it can be written over a limited number of times. This encoding is called a WOM-code (Write-Once Memory Code) and it could be really useful for a bootloader, if it wasn’t for the fact that the property that WOM-codes rely on is inherently incompatible with error-correcting codes:
Let code(x) be an error-correcting code, such that if y can be written over x using the rules of flash memory (ie, ), then code(y) can be written over code(x): .
Then, consider the following sequence, of codes:
u( 0 ) = code(111...111)
u( 1 ) = code(111...110)
u( 2 ) = code(111...100)
...
u(n-2) = code(110...000)
u(n-1) = code(100...000)
u( n ) = code(000...000)
From the property of error-correcting codes, the Hamming distance between and must be greater than or equal to 2.
You can then convince yourself that from the property we assumed:
We have .
Repeating this step throughout, this means that : the code needed to have at least as many error-checking bits as it has contentful bits. Very wasteful!
This doesn’t mean that it’s impossible to make an error-correcting code that is compatible with a WOM-code, only that those two would have to be carefully designed together.
The full algorithm
That was quite the journey so far!
Yes, but thanks to our efforts, we now have a working algorithm to efficiently update our application, while being resilient to sudden shutdowns.
This is in fact the same algorithm that is used in MCUBoot (its version copies the rightmost chunks first), and in other smaller bootloaders like embassy-boot:
# Prepare a journal of `3 * #CHUNKS` flash words
journal_size = 3 * len(CHUNKS)
prepare_journal(words=journal_size)
for chunk in CHUNKS:
# Step 1: copy from version A to scratch
copy(version_a[chunk], scratch)
write_to_journal(chunk, step=1)
# Step 2: copy from version B to version A
copy(version_b[chunk], version_a[chunk])
write_to_journal(chunk, step=2)
# Step 3: copy from scratch to version B
copy(scratch, version_b[chunk])
write_to_journal(chunk, step=3)
I don’t know of an official name for this algorithm, but I like to call it “swap with scratch” or just “scratch-swap”.
This algorithm is essential to Polyboot, but by itself, it is still limited: it only knows how to update, not where and when to update.
In the next article, we will see how to make this algorithm fit within the rest of a bootloader, and get to a first working bootloader!